A Neural Machine Translation Approach for Translating Different Languages in English
-
Nusrat Jahan Suha
Department of Information and Communication Engineering, Noakhali Science and Technology University, Noakhali 3814, Bangladesh
Mohammad Ashikur Rahman Khan
Department of Information and Communication Engineering, Noakhali Science and Technology University, Noakhali 3814, Bangladesh
Mohammad Sharif HossainDepartment of Information and Communication Engineering, Noakhali Science and Technology University, Noakhali 3814, Bangladesh
| Received 29 Apr, 2023 |
Accepted 26 Sep, 2023 |
Published 18 Oct, 2023 |
Background and Objective: Neural Machine Translation (NMT) is capable of predicting the likely consequences of a given string of words. Twenty-seven languages were used in the study and by using these 27 language datasets, the model translation capacity has been evaluated. Some sentences of every language compared with the output of Gogle Translate. Materials and Methods: A recurrent neural network named long short-term memory has been used. Here, the ADAM optimization algorithm and Soft Max Activation function have been used. The BLEU (Bilingual Evaluation Understudy) is used for evaluating translation quality. Results: The research has shown that Western languages have given better BLEU (Bilingual Evaluation Understudy) scores than Asian languages. Especially the Latin script languages have given better translation quality than other script languages. Among 27 languages, the research has worked with four languages whose translations even do not add the Google translator. The translation quality is good according to the BLEU score matrix algorithm. The established neural machine translation system has given a good translation in these aspects. Conclusion: So, in this research, 27 languages are translated into English by the Neural Machine Translation model. The research can contribute to the field of machine translation.
| Copyright © 2023 Suha et al. This is an open-access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |
INTRODUCTION
The use of computers for machine translation involves translating text from one language into another. The complexity of MT (machine translation) is caused by a variety of elements. It is such as words with numerous meanings and sentences with various grammatical patterns. Here, neural machine translation is used to translate different languages to English which is used as a recurrent neural network.
Neural machine translation is an artificial neural network. This network estimates the possibility of word sequences. Usually, it is formed of full sentences. Some of the essential problems are given below that are associated with machine translation.
| • | Quality issues | |
| • | Lack of creativity | |
| • | Lack of sensitivity | |
| • | Multiple meanings in translation | |
| • | Translating language structure | |
| • | Translating idioms and expressions | |
| • | Missing names in translation | |
| • | Translating sarcasm | |
| • | NMT does not work well with small datasets | |
| • | NMT performs badly without-of-domain data | |
| • | NMT performs poorly for rare words |
The research established machine translation system that is good for translating different languages into English. It is vital to work with machine translation and try to solve their problems.
The study shows that translations between English and German, Afrikaans, Portuguese, Spanish, Danish, Greek, Polish, Hungarian, Finnish and Chinese tend to be the most accurate1. Another study suggests neural machine translation that is multi-way and multilingual. To translate between several languages, a single neural translation model is used. The researcher simultaneously trained the suggested multi-way, multilingual model on ten language pairings from WMT’15. Additionally, the researcher notices definite performance gains over models trained on just one language pair2. A straightforward fix for employing a single neural machine translation (NMT) model suggested translating between many languages3. Multilingual models of up to 12 language pairings on the production corpus provide a more accurate translation of several individual pairs. In this study4, the authors create a diagnostic technique to identify Gestational Diabetes Mellitus (GDM) and prevent difficulties for both the mother and the fetus. The same patient dataset was used. The datasets are used to examine how well other Artificial Neural Network models perform. This study developed an Android app to determine if a person has asthma or not5. Additionally, it can provide therapy to asthmatic patients using these Android applications. Different types of machine learning methods have been used to establish this. The networks are employed to categorize breast cancer tumors and identify breast cancer6. A number of artificial neural networks are used for the classification of benign and malignant. A multilayer feed forward-back propagation approach is suggested by Khan et al.7. It was implemented to create an ANN model to forecast the stock market. The Leven Berg-Marquardt algorithm (LM) yields the best results for the suggested model. The study8 used EBMT to convert UN-translated words into Bangla WorldNet and IPA-based transliteration. The system additionally employs the Akkhor translation process. The research paper used recurrent neural networks, Long Short Term Memory (LSTM), The Gated Recurrent Unit (GRU) and Soft Max activation functions. The GRU performs better than LSTM. This paper only focuses on English-to-Bangla translation9. Decision trees and other multilayer perceptron neural networks are employed to predict dengue epidemics10. Here, the research established that Levenberg-Marquardt is the most effective method and discovered 97.3% accuracy and 2.7% inaccuracy in predicting Dengue illness. Machine translation is an aspect of this modern world. But the translation is not an easy task. In the modern world, English is an international language and mandatory for communication. Twenty-seven languages have been used, as well as four uncommon languages, for translating into English. The comparison of sentence by sentence with the Google translator also happened. So, the research paper is aimed at translation from different languages to English.
MATERIALS AND METHODS
Study area: This study was conducted in the Computer Laboratory, Department of Information and Communication Engineering laboratory of the Noakhali Science and Technology University. The study was conducted for a period of 150 days (August to December, 2020).
|
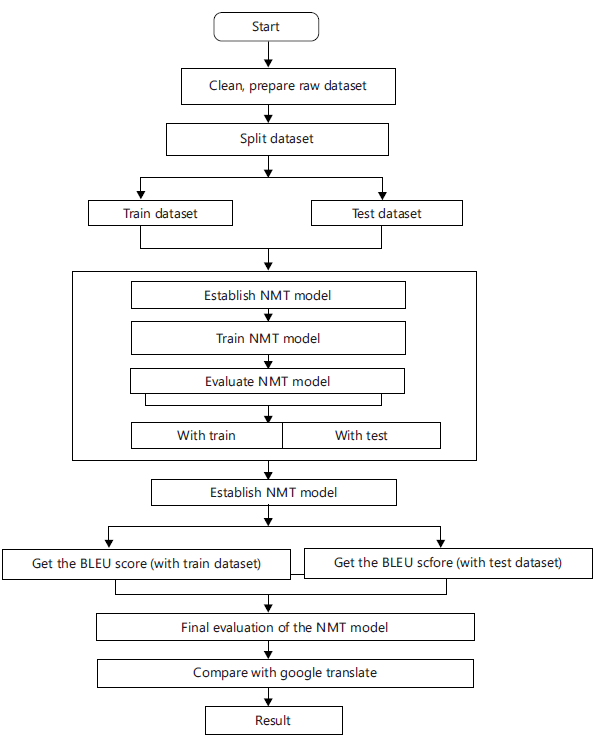
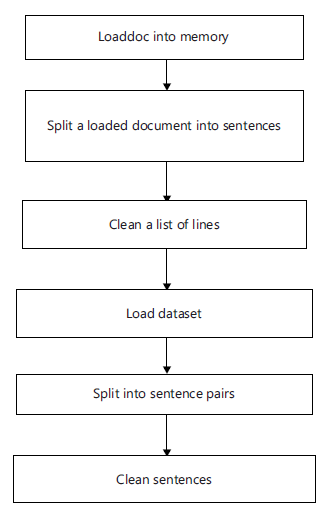
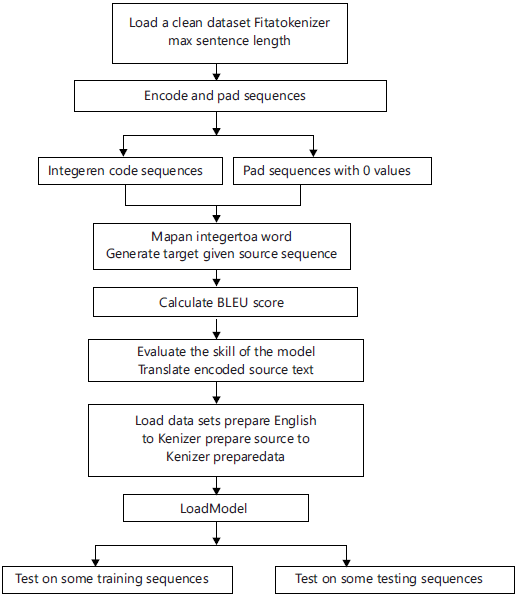
First, the workflow diagram of the overall process has been shown here. The dataset has been prepared for using it in the model. After splitting the dataset into training and testing halves, the raw dataset is created in a way that allows it to be utilized for translation. These are the overall workflow diagram of the process shown in Fig. 1.
Neural machine translation: A sophisticated artificial neural network is used in neural machine translation to forecast the probabilities of word patterns, often in the form of complete sentences. Unlike statistical machine translation, which requires more memory and processing time, neural machine translation (NMT) trains every component from beginning to end to achieve the best performance.
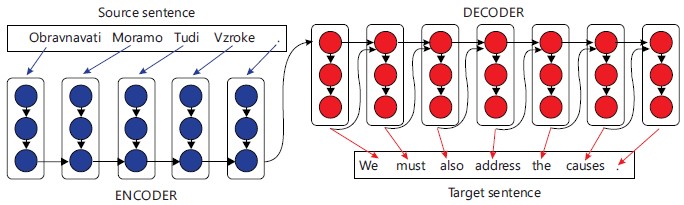
The NMT processes a source phrase into vectors for a second recurrent neural network, the decoder. To predict words in the target language using a recurrent neural network, also known as an encoder. Figure 2 shows the encoder-decoder model.
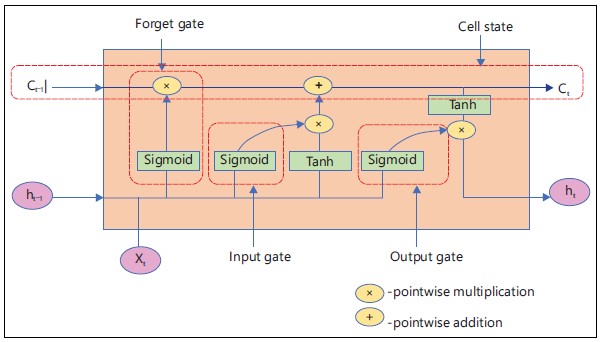
Long short-term memory: Deep learning uses the artificial recurrent neural network (RNN) architecture known as Long Short-Term Memory (LSTM). The LSTM has feedback connections in contrast to conventional feed-forward neural networks. Figure 3 shows LSTM architecture.
|
|
Optimization is a search process that can be thought of this search as learning. The ADAM optimization algorithm is used in this research. An activation function is called Soft Max. An activation function in a neural network describes how a node or nodes in a network translate the weighted sum of the input into an output. They choose whether or not to activate the neuron.
Datasets details: Tab-delimited Bilingual Sentence Pairs are used for datasets. Tatoeba corpus is the source of the sentence pairs. The data set is available from the many Things. orgwebsite, with examples drawn from the Tatoeba Project. Tatoeba Corpus imported 300,000 sentences from the Tanaka Corpus. To establish the translation, process a huge amount of language pairs and various datasets are used in this research.
All languages do not have the same datasets as show in Table 1. As mentioned before four un common languages are used here for English translation. The datasets for these languages have given below in Table 2.
The search has been done further in 14 languages. The translation gives a good translation quality in most of all language translator platforms. The reason for using these popular languages is to completely manifest the ability of the model. Table 3 gives the list of the language datasets.
The primary concern of this research is to improve the translation quality of the languages that are difficult to translate into English. However, the process, methodology and implementation are the same as in the other languages. The research has happened deeply with other languages which need to improve translation quality.
| Table 1: | Language dataset for the 10 languages | |||
| Languages | Full dataset |
Train dataset |
Test dataset |
| Bengali | 4332 |
3332 |
1000 |
| Marathi | 20000 |
19000 |
1000 |
| Thai | 2910 |
2000 |
910 |
| Arabic | 11584 |
9000 |
1000 |
| Danish | 10000 |
9000 |
1000 |
| Romanian | 10000 |
9000 |
1000 |
| Czech | 10000 |
9000 |
1000 |
| Vietnam | 6139 |
5000 |
1139 |
| Icelandic | 6558 |
6000 |
558 |
| Macedonian | 30000 |
29000 |
1000 |
| Table 2: | Language dataset for the uncommon languages | |||
| Languages | Full dataset |
Train dataset |
Test dataset |
| Kabyle | 20000 |
18000 |
2000 |
| Low German | 3206 |
3000 |
206 |
| Tagalog | 3665 |
3000 |
665 |
| Cantonese | 3255 |
3000 |
255 |
| Table 3: | Language dataset for the common languages | |||
| Language | Full dataset |
Train dataset |
Test dataset |
| Turkish | 10000 |
9000 |
1000 |
| German | 10000 |
9000 |
1000 |
| Swedish | 10000 |
9000 |
1000 |
| French | 10000 |
9000 |
1000 |
| Portuguese | 10000 |
9000 |
1000 |
| Spanish | 10000 |
9000 |
1000 |
| Japanese | 10000 |
9000 |
1000 |
| Greek | 10000 |
9000 |
1000 |
| Bulgarian | 10000 |
9000 |
1000 |
| Finish | 10000 |
9000 |
1000 |
| Indonesian | 7141 |
6000 |
1141 |
| Azerbaijani | 2192 |
2000 |
192 |
| Norwegian | 6015 |
5000 |
1015 |
Accuracy testing: A tool for assessing the accuracy of text that has been machine-translated from one natural language to another is called BLEU (Bilingual Evaluation Understudy). The characteristic requires consideration of the similarity between a machine’s and a human’s output. The better a machine translation is, the nearer it comes to an accurate human translation. The research has used the BLEU score for evaluating the translation quality.
Implementation: The Google co-lab is used for implementation. The SciPy environment for Python 3 has been installed. The SciPy is a library for scientific computation. Scientific Python is the full form of Scipy. Different types of Python packages are used for this. Tensorflow, Keras, tokenizer, pickle, NLTK (Natural Language Toolkit), NumPy, Matplotlib, etc. are used for translating from a different language to English. A Python module used for natural language processing is called NLTK. Tokenization, as it is known in Python, is the process of breaking up a larger body of text into smaller lines, words, or even brand-new words for languages other than English. A well-liked format for serializing and desterilizing data types is the Pickle module for Python. A Python interface for artificial neural networks is provided by the open-source library Keras. For the Tensor Flow library, Keras serves as an interface. A machine learning and artificial intelligence software library called TensorFlow is free and open-source. For the Python programming language and its NumPy extension for numerical mathematics, there is a graphing library called Matplotlib. Array manipulation is done using the NumPy Python library.
|
Mainly 4 steps are used for implementation.
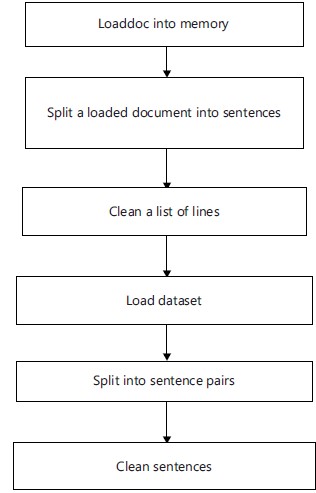
Data preparation: There search cannot be done with the raw datasets. Figure 4 shows the flow chart for preparing the text. The preparation of datasets is divided into 2 sections. These are text cleaning and text splitting. Text cleaning means preparing the raw datasets for the model to translate from one language to another. For translation, reading and processing the data is a must. The train dataset is used to train the model and the test dataset is used to test the model. The dataset size can be fixed. Sometimes for some language datasets , the whole dataset is not used. Some portion of the dataset is used.
Figure 5 shows a Flow chart of split text.
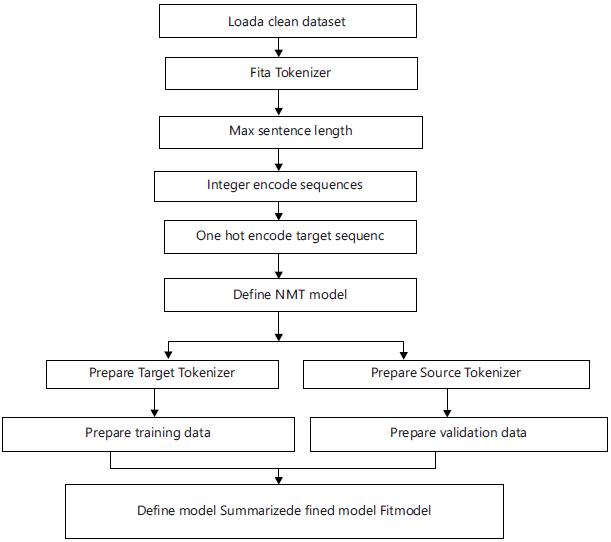
Train and test the model: The overall flowchart of the train and tests the model. The model configuration was not optimized for this problem, meaning that there is plenty of opportunities for us to tune it and lift the skill of the translations as shown in Fig. 6.
Figure 6 shows the overall flowchart of the train and test model.
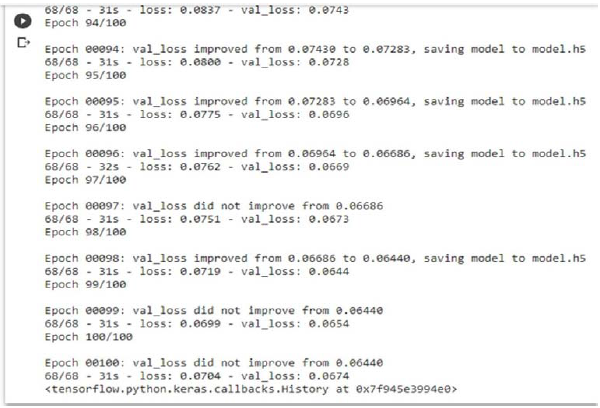
Figure 7 is a screenshot of the epoch process during the train model. This is the output of the code executed by the author during train the NMT (Neural Machine Translation) model. The number of epochs is hyperparameter controls how many times the learning algorithm will run through the full training datasets. The code has been written in python programming language. The complete source code for this research has been posted to Github. The uploaded code has been set as public.
|
|
After the epoch process, the model is trained. Each epoch takes about 30 sec on modern CPU hardware. No GPU (Graphics Processing Unit) is required. In the checkpoint, the validation loss has been monitored and the mode is min. Word Embedding is a Collective term for models that learned to map a set of words or phrases in a vocabulary to vectors of numerical values.
|
|
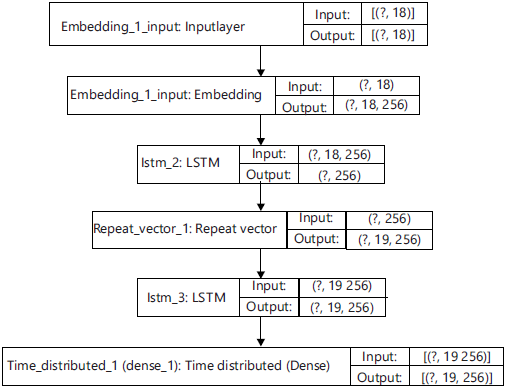
The plot model graph of the NMT has been illustrated in Fig. 7.
Evaluate the neural translation model: Evaluation involves 2 steps: First generating a translated output sequence and then repeating this process for many input examples. The skill of the model has been summarized across multiple cases.
Figure 9 shows the Flow chart for evaluating the machine translation system.
The model is trained again and again and every time two LSTM layer is used. Every LSTM contains four layers. This means 8 layers from two LSTM layers, have been used in these models.
|
RESULTS
Different languages have given different translation qualities. But in this research Fourteen languages translation quality has been measured and analyzed properly. In both training and testing, the target sentence is compared with the predicted sentence according to the source sentence. Then different languages’ translation quality has manifested according to Google translator with samples of sentences by sentences.
BLEU score for languages available in google translation: The BLEU score of different languages for translating into English is given in Table 4. In Table 4 Ten languages translation quality has been shown according to the BLEU score. The Ten languages are Bengali, Romanian, Danish, Czech, Arabic, Thai, Marathi, Vietnamese, Icelandic and Macedonian. Among them, Macedonian language quality is the lowest. For Bengali, Romanian, Danish and Czech BLEU (Bilingual Evaluation Understudy) scores are up to 0.80. The range is from 0.82 to 0.86. Arabic and Vietnamese language BLEU score is from 0.52 to 0.56. The Icelandic language BLEU score is 0.64. This BLEU score is better than in Arabic and Vietnamese Languages. Thai, Marathi and Macedonian BLEU score is from 0.40 to 0.30. The BLEU score has been found between 0.86 to 0.30 for these ten languages. Among these ten languages, Romanian has the highest BLEU score and Macedonian has the lowest.
Comparison of few common languages: Thirteen different languages have also been used to translate into English. These are Turkish, German, French, Swedish, Portuguese, Spanish, Japanese, Greek, Bulgarian, Finish, Indonesian, Azerbaijani and Norwegian. The established model also worked well with these languages. For these languages, Google Translate has already given the best translation quality. For these reasons, there search has not been analyzed deeply by using these language datasets. Table 5 have shown the BLEU score for these languages in the established model. The Turkish, German, French, Portuguese and Bulgarian languages’ BLEU scores are from 0.43 to 0.49. Spanish, Finish and Indonesian Languages BLEU scores are 0.53, 0.60 and 0.76 in some respects. The BLEU score of Azerbaijani, Norwegian, Swedish, Japanese and Greek BLEU scores are from 0.33 to 0.38. Among these thirteen languages, Indonesian has the highest BLEU score and Azerbaijani has the lowest.
| Table 4: | Translation quality of the ten languages according to BLEU score | |||
| Language | BLEU score |
| Bengali | 0.825149 |
| Romanian | 0.862303 |
| Danish | 0.821216 |
| Czech | 0.86676 |
| Arabic | 0.56517 |
| Thai | 0.368639 |
| Marathi | 0.404108 |
| Vietnamese | 0.528193 |
| Icelandic | 0.647203 |
| Macedonian | 0.308605 |
| Table 5: | Translation quality of the common languages according to BLEU score | |||
| Language | BLEU score |
| Turkish | 0.43465 |
| German | 0.478521 |
| Swedish | 0.33986 |
| French | 0.478799 |
| Portuguese | 0.471336 |
| Spanish | 0.537467 |
| Japanese | 0.387811 |
| Greek | 0.353354 |
| Bulgarian | 0.493094 |
| Finish | 0.600799 |
| Indonesian | 0.765196 |
| Azerbaijani | 0.339542 |
| Norwegian | 0.383382 |
Accuracy for languages not available in Google translation: The established neural translation model has also worked with four uncommon languages for translating English. Google Translate does not even add these languages to its system. These four languages are Kablye, Tagalog, Low German and Cantonese. Among popular translators, Y and ex Translator has added Tagalog for translation. Microsoft Bing translator has added the Cantonese Language for translation. But the other two languages, Kablye and Low German have not been added to any popular translator. The translation quality of the uncommon languages according to the BLEU score is shown in Table 6. The uncommon languages BLEU score Ranges from 0.40 to 0.65. Among them, the Cantonese Language has the best translation quality and Kablye has the worst.
According to the BLEU score interpretation of Fig. 10 as given the proposed model translation quality is good for most of the languages.
Figure 10 has been shown the BLEU score interpretation.
Comparison with example by sentence-to-sentence translation: These sections have shown the disparities between the output of Google Translate and established neural machine translation. Dissimilarities among different sentences have been shown in Table 7-12. Established model translation quality is better for many translations than Google Translator.
|
| Table 6: | Translation quality of the uncommon languages according to BLEU score | |||
| Languages | BLEU score |
| Kabyle | 0.408951 |
| Tagalog | 0.506442 |
| LowSaxon | 0.630855 |
| Cantonese | 0.653991 |
| Table 7: | Comparison between NMT and Google translator for Bengali languages | |||
| Bengali | NMT | Google translate |
| I’m resting my legs | I’m paying my dues, I’m kicking my leg | |
| Call us | Our ducks |
| Table 8: | Comparison between NMT and Google translator for the Arabic language | |||
| Arabic | NMT | Google translate |
| Clock ticked | Watch’s second hand moved | |
| Becareful when you cross a road | Seek caution as you cross the road |
| Table 9: | Comparison between NMT and Google translator for the Thai language | |||
| Thai | NMT | Google translate |
| You can stay till tonight | You can stay until to night | |
| My brother becamea cook | My brother went to cook |
| Table 10: | Comparison between NMT and Google translator for the Marathi language | |||
| Marathi | NMT | Google translate |
| I want it | I want | |
| My cat is missing | My goat has disappeared |
| Table 11: | Comparison between NMT and Google translator for Vietnamese languages | |||
| Vietnam | NMT | Google translate |
| its pay back time | Time to retaliate | |
| Ive madeup my mind to | I decided that from no won I | |
| study harder from no won | would study harder |
| Table 12: | Comparison between NMT and Google translator for Macedonian languages | |||
| Macedonian | NMT | Google translate |
| Томпростенка | To mgroaned | Tom’s sorry |
| Првагодинасум | I’m just a freshman | This is my first year |
However, the sentence-to-sentence comparison has also been made so that any one can underst stand the problem that is associated with machine translation systems now a days.
DISCUSSION
Twenty-seven Languages have been used in this research. The research has worked with the recurrent neural network, LSTM (Long Short-Term Memory) to translate from different languages to English. The research has also worked with distinctive languages kablye, low Saxon, Cantonese and Tagalog. The translation is not available in the most popular and most used Google translator. In this research, it has been found that most Asian languages are hard to translate. But European or non-Asian language BLEU scores are good. Most of the Latin-script language has given higher translation quality. A translation difference between the established translation system and Google Translator has been found. For some languages, the meaning of the languages has been reversed in Google Translate.
Park et al.13 reported an ancient Korean neural machine translation where the BLEU score is 29.92 points. By using n-gram blocking and ensemble models the BLEU point improves to 32.57. Das et al.14 proposed a model comprised of two MNMT systems. One is for English-Indic (one-to-many) and the other for Indic-English (many-to-one). The 15 language pairs with 30 translation directions have been used. For English to Indic Language translation, The MNMT model gives a BLEU score between 6.6 and 29.90 BLEU score. For Indic Language to English direction, the BLEU score ranges between 14.0 to 49.3. A unidirectional translation from Kannada to English with neural machine translation has been established by Nagaraj et al.15 the paper received the highest BLEU score of 17.3815. Dedes et al.16 the models proposed with the applied Long Short-Term Memory Method. It has worked with 47 bilingual food recipes between Spanish-English and English-Spanish. The comparing results show that the translation of recipes from Spanish-English has a better BLEU value of 0.998426. From English to Spanish, the BLEU value is 0.997175. The researcher17 propose a neural machine translation (NMT) system for 4 language pairs. The language pairs are English-Malayalam, English-Hindi, English-Tamil and English-Punjabi. The BLEU score for these languages ranges from 10.15 to 27.12. Long short-term memory (LSTM) and bi-directional recurrent neural networks (Bi-RNN) were used in the NMT architecture. The proposed approach18 can achieve a 24.13 BLEU score on Singlish-English by seeing ~0.26 M parallel sentence pairs with 50 K+ word vocabulary. This research addresses the challenge of preparing a data set to evaluate the deep learning approach’s performance for the machine translation activity for Singlish to English language translation and to evaluate the Seq2Seq Neural Machine Translation (NMT) model. The work19 neural machine translation for translating English-Punjabi. Here the BLEU score of their work is 26.07. Many research works have been done similarly to the paper, but something makes a difference. Any of the research has not worked in so many varieties of languages. Using 27 different types of languages for translation is a big step and a significant advantage of machine translation. But the research paper has worked with many languages and gets a satisfactory BLEU score. No journal papers have been found with working uncommon (kablye, low Saxon and Tagalog) languages that have worked here. But the shortcoming of the study is it has worked only one-way translation, different languages to English. And the other thing is it has not built multilingual neural machine translation. The translation is not two-way. The established model has the scope to translate the languages into English, but the model does not keep the scope of translation from English to a different language. The research has only used one algorithm for evaluating translation quality. Other than that, using different evaluation matrix algorithms will give a strong base for this research.
CONCLUSION
The research paves the way for working more and more with neural machine translation systems in language translation so that the improvement of machine translation can go further compared with human evaluation. The research has worked with four languages whose English translation is not available in Google Translate. The average BLEU score is found to be 0.55. The score indicates the high translation quality. Another translation of 10 different languages to English is also shown. The average BLEU score of these languages is 0.619735, indicating a very good quality translation. In the future, with larger datasets, the accuracy will be better by using this neural translation model. Bi-directional LSTM can be used for further improvement.
SIGNIFICANCE STATEMENT
This research paper has worked with Twenty-seven languages. Among them, four language translations even do not add the Google translator. The research has also shown that Western languages have given better BLEU scores than Asian languages. The average BLEU score of all languages is 0.535607, indicating a very good-quality translation. For some languages, the proposed and established model has given a better BLEU score than Google Translator. The purpose of this work is to make a machine translation system where every language can easily be translated into English. The study also focuses on the translation difference between the established model and Google translation.
ACKNOWLEDGMENT
The authors would like to acknowledge Research Cell, Noakhali Science and Technology University, Noakhali for their support.
REFERENCES
- Aiken, M., 2019. An updated evaluation of google translate accuracy. Stud. Ling. Lit., 3: 253-260.
- Firat, O., K. Cho, B. Sankaran, F.T.Y. Vural and Y. Bengio, 2017. Multi-way, multilingual neural machine translation. Comput. Speech Lang., 45: 236-252.
- Johnson, M., M. Schuster, Q.V. Le, M. Krikun and Y. Wu et al., 2017. Google’s multilingual neural machine translation system: Enabling zero-shot translation. Trans. Assoc. Comput. Ling., 5: 339-351.
- Hera, T.R., M.A.R. Khan and N. Nath, 2021. Early gestational diabetes detection using neural network. WSEAS Trans. Biol. Biomed., 18: 1-17.
- Murad, S.A., A. Adhikary, A.J.M. Muzahid, M.M.H. Sarker and M.A.R. Khan et al., 2022. AI powered asthma prediction towards treatment formulation: An android app approach. Intell. Autom. Soft Comput., 34: 87-103.
- Sultana, Z., M.A.R. Khan and N. Jahan, 2021. Early breast cancer detection utilizing artificial neural network. WSEAS Trans. Biol. Biomed., 18: 32-42.
- Khan, M.A.R., M.F. Uzzaman, I. Ahammad, R. Prosad and Z.U. Salehin et al., 2022. Stock market prediction in Bangladesh perspective using artificial neural network. Int. J. Adv. Technol. Eng. Explor., 9: 1397-1427.
- Salam, K.M.A., S. Yamada and T. Nishino, 2013. How to translate unknown words for English to Bangla machine translation using transliteration. J. Comput., 8: 1167-1174.
- Siddique, S., T. Ahmed, M.R.A. Talukder and M. Mohsin Uddin, 2020. English to Bangla machine translation using recurrent neural network. Int. J. Future Comput. Commun., 9: 46-51.
- Khan, M.A.R., J. Akter, I. Ahammad, S. Ejaz and T.J. Khan, 2022. Dengue outbreaks prediction in Bangladesh perspective using distinct multilayer perceptron NN and decision tree. Health Inf. Sci. Syst., 10.
- Maučec, M.S. and G. Donaj, 2020. Machine Translation and the Evaluation of Its Quality. In: Recent Trends in Computational Intelligence, Sadollah, A. and T. Sinha (Eds.), IntechOpen, London, UK, ISBN: 978-1-83880-706-1.
- Kugathasan, A. and S. Sumathipala, 2022. Neural machine translation for Sinhala-English code-mixed text. Int. J. Adv. ICT Emerging Countries, 15: 60-71.
- Park, C., C. Lee, Y. Yang and H. Lim, 2020. Ancient Korean neural machine translation. IEEE Access, 8: 116617-116625.
- Das, S.B., A. Biradar, T.K. Mishra and B.K. Patra, 2023. Improving multilingual neural machine translation system for indic languages. ACM Trans. Asian Low-Resour. Lang. Inf. Process., 22.
- Nagaraj, P.K., K.S. Ravikumar, M.S. Kasyap, M.H.S. Murthy and J. Paul, 2021. Kannada to English machine translation using deep neural network. Ingénierie Systèmes d’Information, 26: 123-127.
- Dedes, K., A.B.P. Utama, A.P. Wibawa, A.N. Afandi, A.N. Handayani and L. Hernandez, 2022. Neural machine translation of Spanish-English food recipes using LSTM. JOIV: Int. J. Inf. Visualization, 6: 290-297.
- Premjith, B., M.A. Kumar and K.P. Soman, 2019. Neural machine translation system for English to Indian language translation using MTIL parallel corpus. J. Intell. Syst., 28: 387-398.
- Sandaruwan, D., S. Sumathipala and S. Fernando, 2021. Neural machine translation approach for Singlish to English translation. Int. J. Adv. ICT Emerging Countries, 14: 36-42.
- Singh, S., M.A. Kumar and K.P. Soman, 2018. Attention based English to Punjabi neural machine translation. J. Intell. Fuzzy Syst., 34: 1551-1559.
How to Cite this paper?
APA-7 Style
Suha,
N.J., Khan,
M.A., Hossain,
M.S. (2023). A Neural Machine Translation Approach for Translating Different Languages in English. Trends in Applied Sciences Research, 18(1), 169-182. https://doi.org/10.3923/tasr.2023.169.182
ACS Style
Suha,
N.J.; Khan,
M.A.; Hossain,
M.S. A Neural Machine Translation Approach for Translating Different Languages in English. Trends Appl. Sci. Res 2023, 18, 169-182. https://doi.org/10.3923/tasr.2023.169.182
AMA Style
Suha
NJ, Khan
MA, Hossain
MS. A Neural Machine Translation Approach for Translating Different Languages in English. Trends in Applied Sciences Research. 2023; 18(1): 169-182. https://doi.org/10.3923/tasr.2023.169.182
Chicago/Turabian Style
Suha, Nusrat, Jahan, Mohammad Ashikur Rahman Khan, and Mohammad Sharif Hossain.
2023. "A Neural Machine Translation Approach for Translating Different Languages in English" Trends in Applied Sciences Research 18, no. 1: 169-182. https://doi.org/10.3923/tasr.2023.169.182

This work is licensed under a Creative Commons Attribution 4.0 International License.